2024/08.13 星期二
?��????????????, ??????????????.
环境的配置主要有三部分: - python的下载 及 环境配置 - 安装 torch ,d2l 及 其他 必要库 - jupyter notebook 的 安装和配置
python的下载地址:python官网
下载python,我个人推荐是使用 anaconda 这个工具。
anaconda的下载地址:anaconda官网
它是一个非常好的python的环境管理工具,可以很方便的管理python的环境,而且它自带了很多的库,可以很方便的安装。这样的话在使用一些较为常用的库的时候就不需要再去下载了。
安装完python之后,我们需要配置python的环境变量,使用非 windows 自带的 store 里面的 python 的话,在调用 python 指令的时候,会优先打开应用商店并推荐下载里面的python,但是实际上我们已经安装了python,所以我们需要配置环境变量。下面是配置环境变量的步骤:
一般是在
C:\Users\用户名\AppData\Local\Programs\Python\Python版本号
下面,在cmd中使用 where python 可以查看python的安装路径。

我这里使用的是 anaconda ,我将其安装在了 E:\Anaconda
下面,版本为3.11。
另外,你可以发现,在
C:\Users\用户名\AppData\Local\Micosoft\WindowsApps
下面也有一个python的路径,但是这个路径是一个快捷方式,不是真正的python的安装路径。这个快捷方式指向的是
store 里面的
python。他会打开store里面的安装界面,推荐你下载store里面的python……而且系统默认环境变量的python也是这个路径,就很无语……
可以通过 python --version
查看python的版本,你看,如果查看那个快捷方式的python的版本,它不会显示版本号:

接下来我们需要安装 torch 和 d2l 以及其他的必要库。找到安装的anaconde
的 Anaconda Prompt,在里面输入以下指令:
1 | pip install torch torchvision torchaudio |
这样就安装好了 torch 和 d2l 了。
你可以使用 pip list 查看已经安装的库。
另外,使用 pip 安装 和 使用 conda 安装有一点点区别,conda
安装的库会放在 E:\Anaconda\envs\你的环境\Lib\site-packages
下面,而 pip 安装的库会放在 E:\Anaconda\Lib\site-packages
下面。除非是你需要打包你的软件,否则的话两个实际上都是一样的。
在这里挖一个坑,后面再填:[[pip和conda的区别]]
jupyter notebook 包含了记笔记和运行代码的功能,你可以在查看教程的同时,运行里面镶嵌的代码,并且根据自己的理解修改代码,尝试不同的运行结果,这样可以更好的理解代码的含义。
首先,我们将 D2L Notebooks 的代码下载到本地:
1 | mkdir d2l-zh && cd d2l-zh |
然后,我们需要安装 jupyter notebook,使用以下指令:
1 | pip install jupyter |
这个库实际上 anaconda
里面已经自带了,但是它不在环境变量里面,我们需要将其添加到
环境变量,这样才能够直接执行 jupyter notebook
这个指令。
这里建议使用 everything 这个工具,可以很方便的查找文件,输入
jupyter 就可以找到 junpyter
这个程序的位置,然后将其添加到环境变量即可。
然后,我们就可以使用 在 D2L 的文件夹目录下 执行
jupyter notebook 来打开 jupyter notebook 了。
实际上,学习 深度学习,对于初学者来说,需要的基础知识面很广,比如说微积分,概率论,线性代数等,但是实际上涉及的并不深…
上面的东西刚好 大一 就会学,所以说,对于大一的同学来说,学习这个东西基本上没有障碍……简单回顾一下下面的这些数学符号基本上就差不多了:
本书中使用的符号概述如下。 ### 数字
数据处理主要涉及到两个核心的问题,一个是如何读取数据,另外一个则是如何处理为空的数据。
将数据处理之后我们还需要将其转换为
在Python中,我们可以使用pandas库来读取数据,pandas库提供了read_csv函数,可以读取csv文件,返回一个DataFrame对象。
作为实例,我们创建一个人工数据集,然后将其保存为csv文件,然后使用pandas库读取数据。
1 | import os |
在panda中,数据集中的空数据被标记为NA,在进行机器训练的时候,不能让机器直接处理空数据,所以说我们需要对空数据进行处理,一般有下述几种办法:
1. 删除法 2. 插值法
删除法将带有空数据的行视为无效数据,直接删除,插值法则是用已知数据的平均值或者中位数等来填充空数据。
在这里,我们用插值法来处理空数据。
1 | # 读取输入和输出数据 |
下面逐行解释一下上述代码:
[[data.iloc]]
用于选取数据集中的行和列,data.iloc[:, [0,1]]表示选取所有行和第0、1列的数据,data.iloc[:, 2]表示选取所有行和第2列的数据。
[[data.fillna]]
用于填充空数据,tempRaw.fillna(tempRaw.mean())表示用
该列的平均值 填充 空数据。
[[data.iloc]]
返回的是一个DataFrame对象,我们可以直接对其进行操作,inputs.iloc[:, 0] = tempRaw表示将tempRaw的数据赋值给inputs的第0列。
使用 pandas 读取数据之后,我们得到的数据类型是
pandas 的 DataFrame
对象,我们需要将其转换为张量,才能用于训练。
1 | import torch |
torch.tensor() 使用 numpy 数组 初始化创建一个
张量,inputs.to_numpy() 将 DataFrame
对象转换为 numpy 数组,dtype=float
表示将数据转换为浮点数类型。
数据从 DataFrame -> numpy 数组 ->
张量,完成了数据的转换。
在深度学习中,实际上对于任意的一个模型,都有两个重要的部分: 1. 模型的结构 2. 模型的损失函数
模型的结构定义了模型的计算过程,而损失函数定义了模型的优劣并且指导模型的优化。
线性回归用于解决回归问题,softmax回归用于解决分类问题。
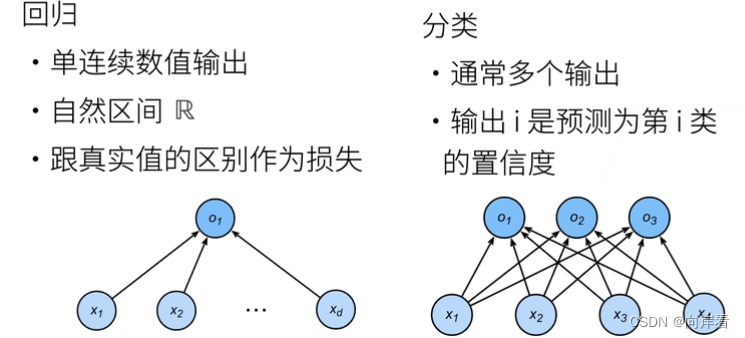
在简单的线性回归中,我们期望模型能够输出一个 标量值,对于 一系列 输入而言,其能够输出符合预期的结果。
softmax 回归也类似,其被用于解决分类问题,我们希望模型能够输出一个n维向量,这个向量的每一个元素代表了输入属于某个类别的概率。
为了达到这样的目的,我们需要引入 softmax 函数,其能够将模型的输出转换为概率。softmax 函数的定义如下: \[softmax(x)_i = \frac{exp(x_i)}{\sum_{j=1}^{n}exp(x_j)}\]
其中,\(x\) 为模型的输出,\(n\) 为类别的数量,\(softmax(x)_i\) 代表了输入属于第 \(i\) 个类别的概率。这个函数的优点在于,其能够保持输出的概率和为1,并且各个概率值都在0到1之间。另外,由于 \(exp(x)\) 是一个非线性函数,因此 softmax 函数也是一个非线性函数,这使得模型对于较大的输入值更加敏感,从而能够更好地区分不同的类别。
soft函数很好的解决了从模型的输出到概率的转换问题,
但是这样也引出来了另一个问题,为了优化参数,我们需要定义一个损失函数,但是对于分类问题,我该如何定义损失函数呢?这里我们引入了交叉熵损失函数,其定义如下:
\[H(y, \hat{y}) = -\sum_{i=1}^{n}y_i\log(\hat{y}_i)\]
其中,\(y\) 为真实的标签,\(\hat{y}\) 为模型的输出,\(n\) 为类别的数量。
这个损失函数的优点在于,其能够衡量模型的输出与真实标签之间的差距,当模型的输出与真实标签完全一致时,交叉熵损失函数的值为0,当模型的输出与真实标签差距越大时,交叉熵损失函数的值也越大。
对于分类问题,我们期望的输出 应当是 除了真实标签之外,其他标签的概率都应该接近于0,而真实标签的概率应该接近于1。通过计算交叉熵损失函数,我们就能够衡量模型的输出与真实标签之间的差距,从而指导模型的优化。
在 神经网络 中,训练的本质实际上是优化参数,使得模型的预测值与真实值之间的误差尽可能小。通过定义损失函数的方式,我们可以知道 参数 与 结果 之间的关系,通过求导的方式, 我们可以知道如何调整参数使得损失函数最小。
假设损失函数为 \(L(\theta)\),那么我们的目标就是找到一个 \(\theta\) 使得 \(L(\theta)\) 最小。对于一个给定的 \(\theta\),我们可以通过计算 \(L(\theta)\) 得知其的损失,然后我们求导 \(L(\theta)\),得到其在 \(\theta\) 处的梯度 \(\nabla L(\theta)\),然后我们可以通过梯度下降的方式,即 \(\theta = \theta - \alpha \nabla L(\theta)\) 来更新 \(\theta\) 。其中 \(\alpha\) 是学习率,是一个超参数,用来控制每次更新的步长。
上述的方法即为梯度下降法,是一种常用的优化方法。从数学上可以证明,梯度下降最终一定能找到一个局部最优解。
在实际运用的时候,我们经常将多个样本的损失函数的平均值作为最终的损失函数,即 \(L(\theta) = \frac{1}{n} \sum_{i=1}^{n} L(\theta, x_i, y_i)\),其中 \(n\) 为样本的数量,\(x_i\) 为第 \(i\) 个样本的特征,\(y_i\) 为第 \(i\) 个样本的标签。但是这样又引出了另一个问题,即当样本数量很大的时候,我们需要计算所有样本的梯度,这样会导致计算量过大,因此我们通常会采用随机梯度下降法,即每次只计算随机选择的多个样本,然后更新参数,而不是全部样本。
下面,我们生成一个人工数据集,然后使用梯度下降法来拟合这个数据集。
1 | import torch |
接下来,我们定义模型和损失函数。
1 | # 定义模型,这里我们不使用 nn.Module,而是自己手搓 |