药剂工艺:虎头蛇尾的模拟经营游戏
游戏本质上是一个模拟经营类型的游戏,不过,它将制作魔药包装成了在地图上通过搭配路径走迷宫的方式,使得游戏增加了非常大的趣味,再加上本身十分浓厚的模拟属性,让人似乎真的觉得自己是作为一个炼药师,为大家炼药。
游戏的美术独具特色,整体的视效和音效都打磨的非常的好。
但是在游戏的后期,仍然存在不少的问题: 1. 驱动力不足:在游戏的后期,驱动力严重不足,因为做出来的材料并没有基于玩家正反馈,做出的黑化、白化之类的物品似乎只是
游戏本质上是一个模拟经营类型的游戏,不过,它将制作魔药包装成了在地图上通过搭配路径走迷宫的方式,使得游戏增加了非常大的趣味,再加上本身十分浓厚的模拟属性,让人似乎真的觉得自己是作为一个炼药师,为大家炼药。
游戏的美术独具特色,整体的视效和音效都打磨的非常的好。
但是在游戏的后期,仍然存在不少的问题: 1. 驱动力不足:在游戏的后期,驱动力严重不足,因为做出来的材料并没有基于玩家正反馈,做出的黑化、白化之类的物品似乎只是

1 | 网路上给的解决办法: |
首先,我检查了一下 node 和 yarn 的版本,都是正常的,按照网上的说法,应该是没有配置系统路径。但是问题是这玩意是npm的包,安装在 node_modules 里面的,为什么要为其配置系统路径呢?
如果说是因为找不到路径,那么我直接 修改 package.json 里面的 scripts 直接指定路径不就好了吗?
1 | "scripts": { |
其实我也是一通捣鼓之后才解决的,解决办法是:
1 | yarn add serve |
在这之后,运行 yarn serve 能够在网页端启动项目,但是 希望的 应该是 创建一个 electron 窗口,而不是在浏览器中打开。
运行 yarn build 后,它能够正常在 dist 目录下生成文件。
1 | yarn add electron |
安装 electron-builder 的时候,会报错:
1 | error @achrinza/node-ipc@9.2.2: The engine "node" is incompatible with this module. Expected version "8 || 10 || 12 || 14 || 16 || 17". Got "22.11.0" |
这是因为我们的 node 版本太高了,而 electron-builder 不支持这么高的版本,但是实际上无所谓。
输入以下命令,忽略这个错误:
1 | yarn add electron-builder --ignore-engines |
或者将其默认设置为忽略错误:
1 | yarn config set ignore-engines true |
然后再次安装 electron-builder
1 | yarn add electron-builder |
之后问题就解决了,运行yarn electron:serve就能够在
electron 窗口中打开项目了。
在2d横板游戏中,相机的振动是相机设计的很关键的一部分,它和音效一起,为游戏构建了一个直观的反馈的基础。
在这篇文章中,我简单聊聊2d横板游戏中相机的振动设计。我们将会从 相机的震动 这个方面来讨论相机的设计。
游戏中的振动无非是模仿现实中的振动,了解现实中的振动,我们可以更好的设计游戏中的振动。
根据 振动的分类 可以将振动 按照其振动特征,分为以下几种: 1. 简谐振动 2. 阻尼振动 3. 各种非线性振动
如果按照振动的振动规律,又可以按照以下分类方式分为七种: 1. 简谐振动 2. 周期振动 3. 准周期振动 4. 过渡振动 5. 窄频带随机振动 6. 宽频带随机振动 7. 不平稳随机振动
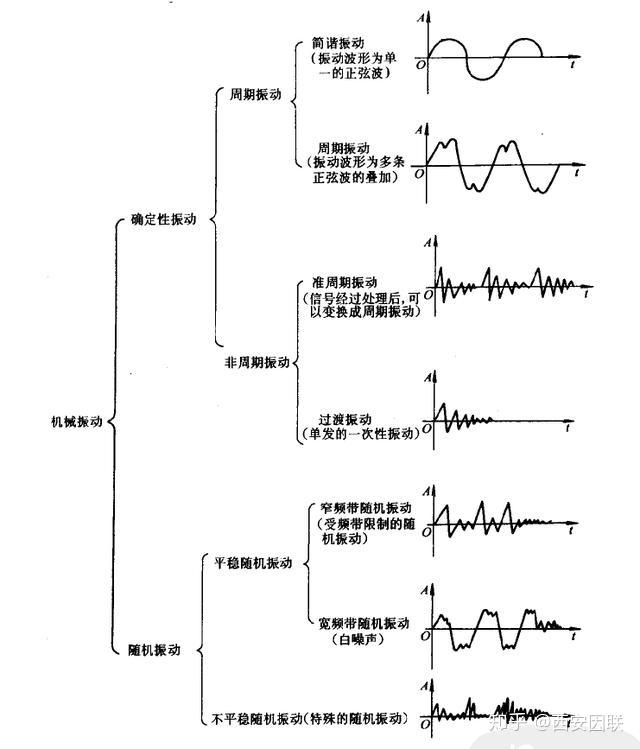
除此之外,我们还可以按照振动的自由度进行分类,简单而言,就是按照振动的方向进行分类,比如说一维振动、二维振动、三维振动等等。
但是实际上,因为相机进行振动的时间往往只是一瞬间,我们从人眼感知的角度而言,实际还是比较难以分辨某种振动属于哪种的。请看下面两种振动:
 这两个一个是窄频带随机振动,一个是不平稳随机振动,但是它们两个的特征就是二者都是高频振动,所以说它们对于人眼来说似乎非常相似。
这两个一个是窄频带随机振动,一个是不平稳随机振动,但是它们两个的特征就是二者都是高频振动,所以说它们对于人眼来说似乎非常相似。
对于我们的大脑来说,识别具体是哪种振动比较困难,但是我们对于振动的频率是非常敏感的。除此之外,我们的大脑还非常擅长于模式识别:

这两个振动明显区别于前面的振动,其中一个是阻尼振动,一个是弹簧振动,它们在频率分布或者振幅分布上拥有特殊的规律。
因为篇幅有限,这里只举例三种比较常见的振动方式
相机的振动一般会使用下面几种方式: 1. 随机偏移震动 2. 随机连续振动 3. 定向弹簧振动
一般会使用上述三种振动进行组合,来达到较为理想的效果
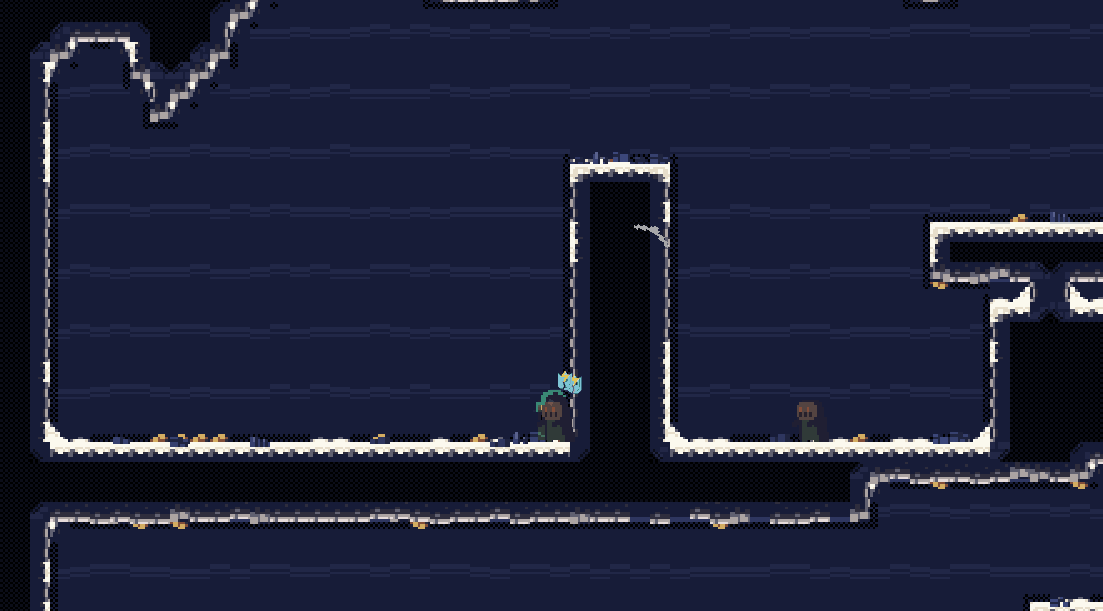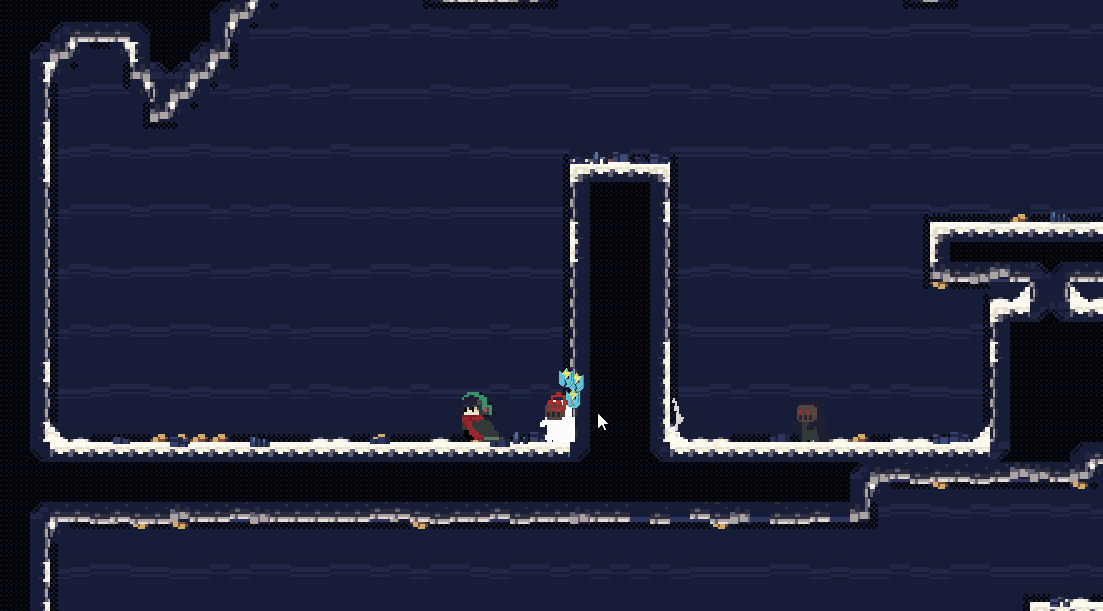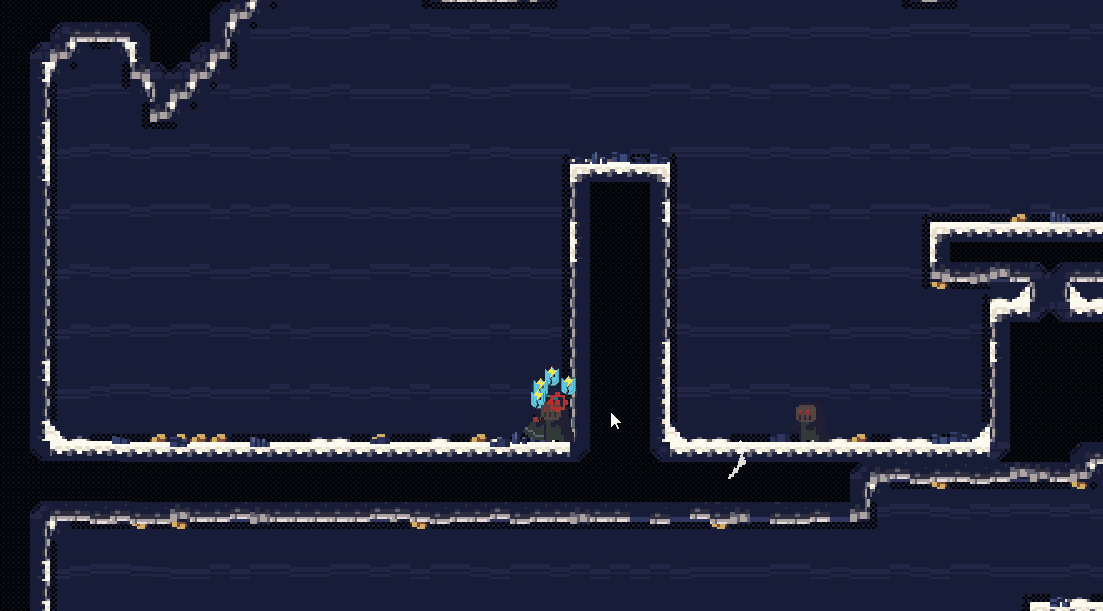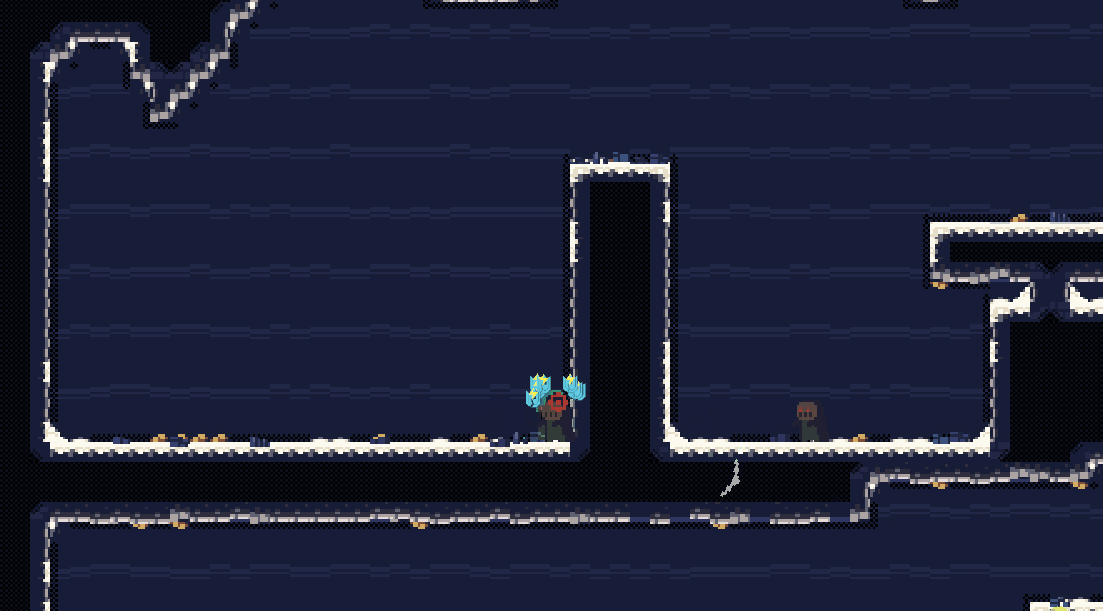
会发现,这种振动会有一点点生硬,但是同时也较为的强烈。
这种振动由随机数生成,每一帧都会有一个随机的偏移量,这样就会产生一个随机的振动效果。随机数的选取可以选择直接的random,但是更好的方式是使用perlin noise,这样可以产生一个更加自然的振动效果。
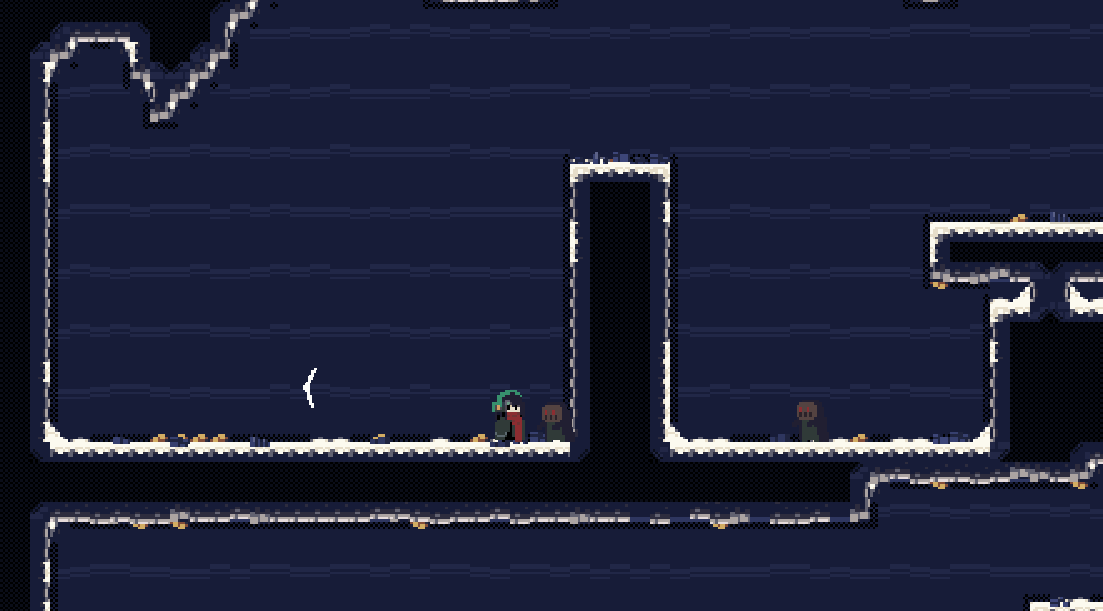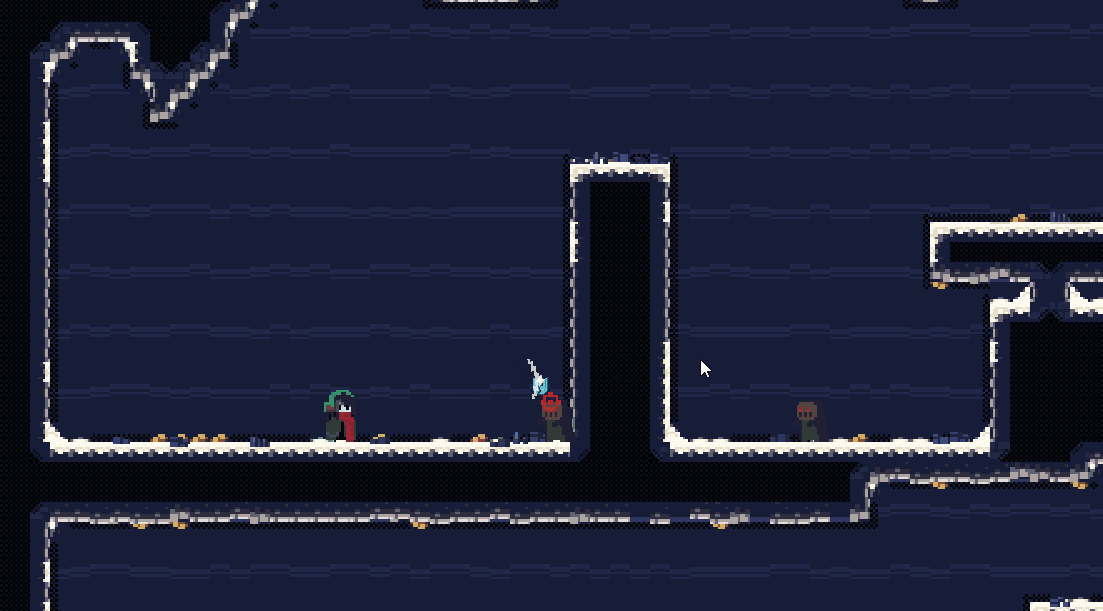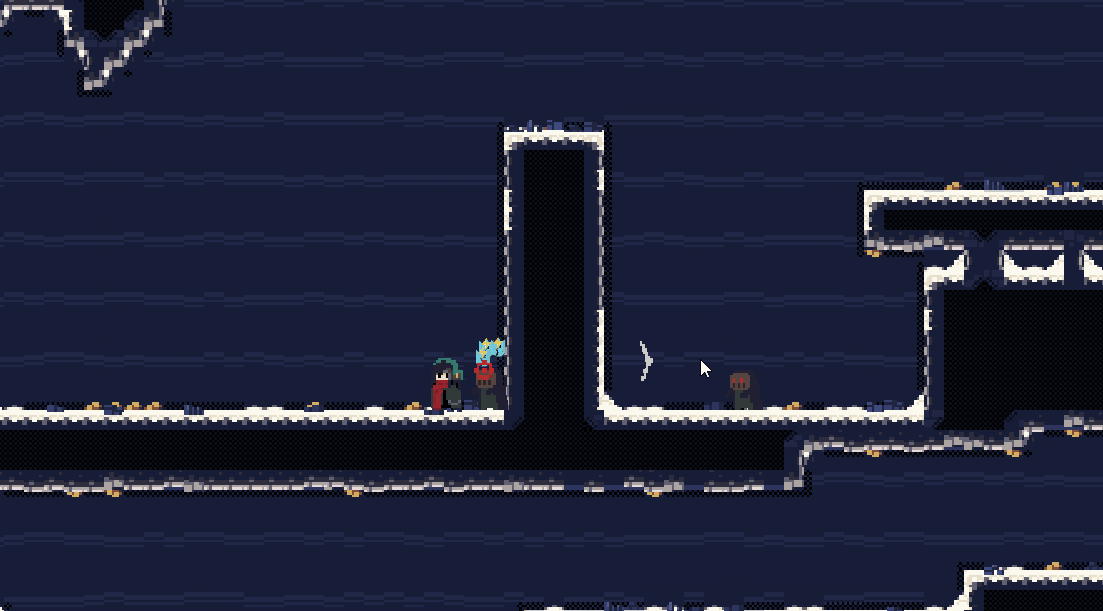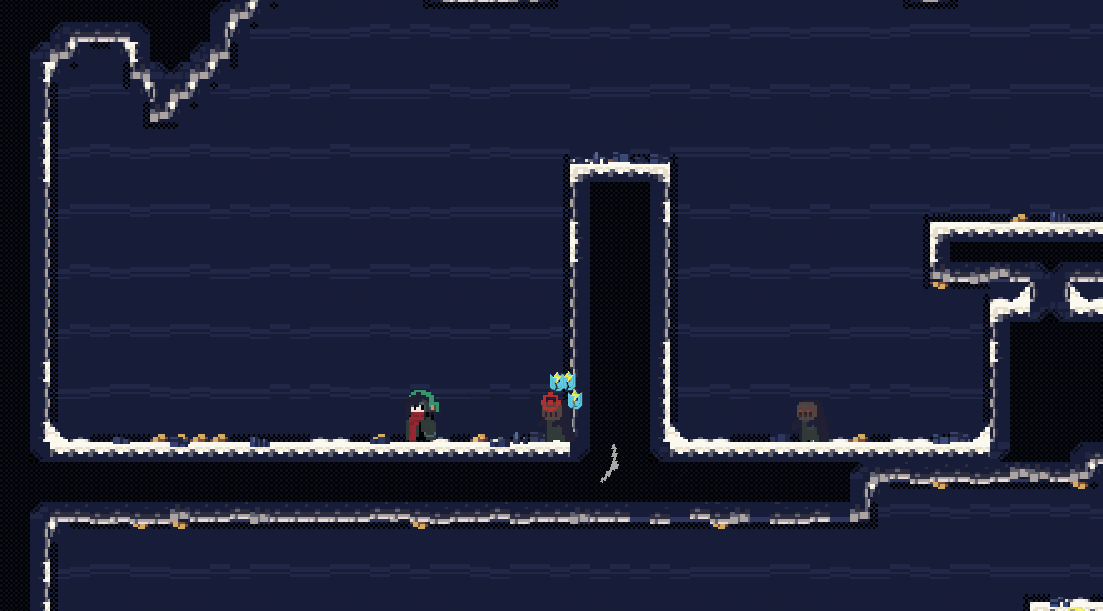
这种振动会比较平滑,但是同时不够强烈。它的特征是由一组连续的数控制振动。
一般会使用 sin/cos 来控制振动的幅度 + 随机步长 来控制振动的幅度,当然也可以直接使用随机的dx,dy来控制振动,但是那样,镜头有一定概率朝一个方向连续移动,需要使用别的方式来限制振动范围和方向。

模仿弹簧,拥有 spring 和 damping 两个参数,控制弹性系数以及阻尼系数。从而产生一个类似于弹簧的振动效果。
它的优势就是方向明确,振动幅度逐渐减小,用来提示受到某个方向的冲击会比较合适。
一般会使用上述三种振动进行组合,来达到较为理想的效果。比如说,当玩家受到攻击时,可以使用定向弹簧振动,当玩家受到爆炸时,可以使用随机连续振动,当玩家受到地震时,可以使用随机偏移震动。
比如下面的这个打击效果就是同时使用了定向的弹簧振动以及较弱的随机连续振动
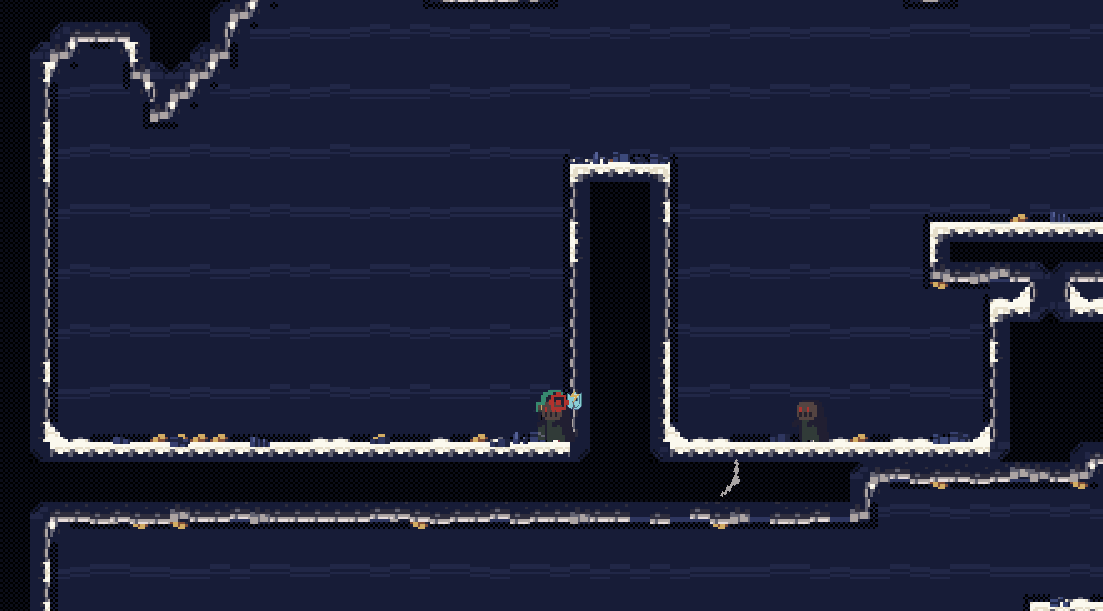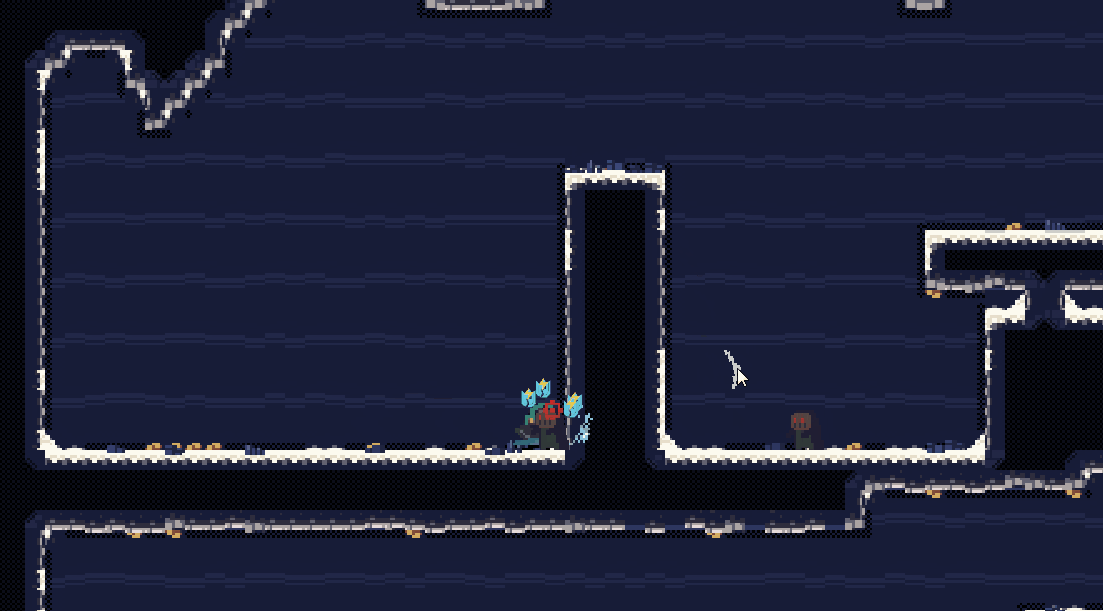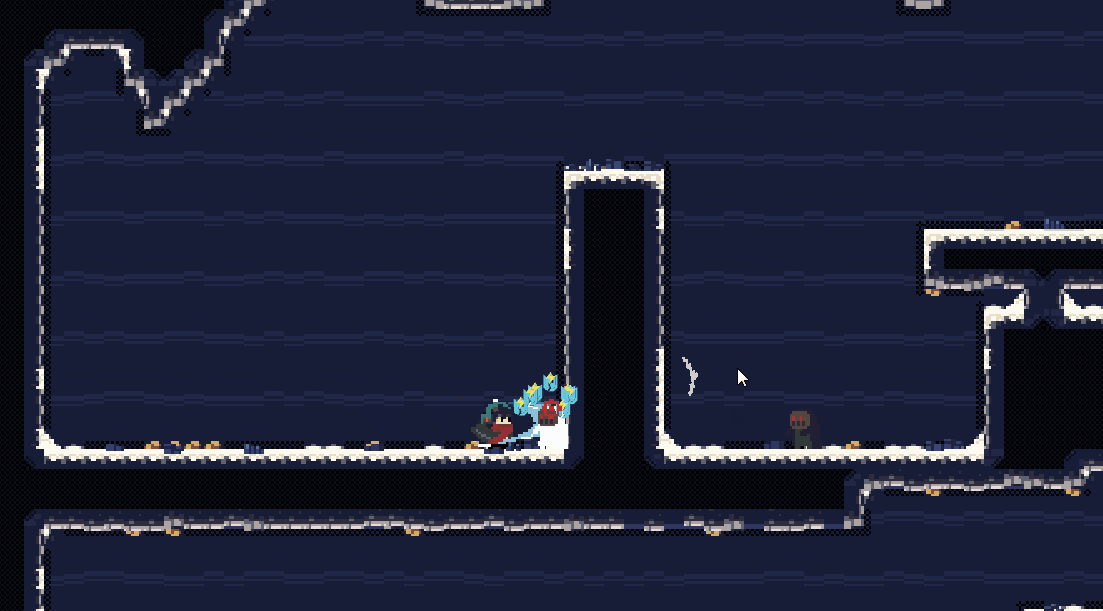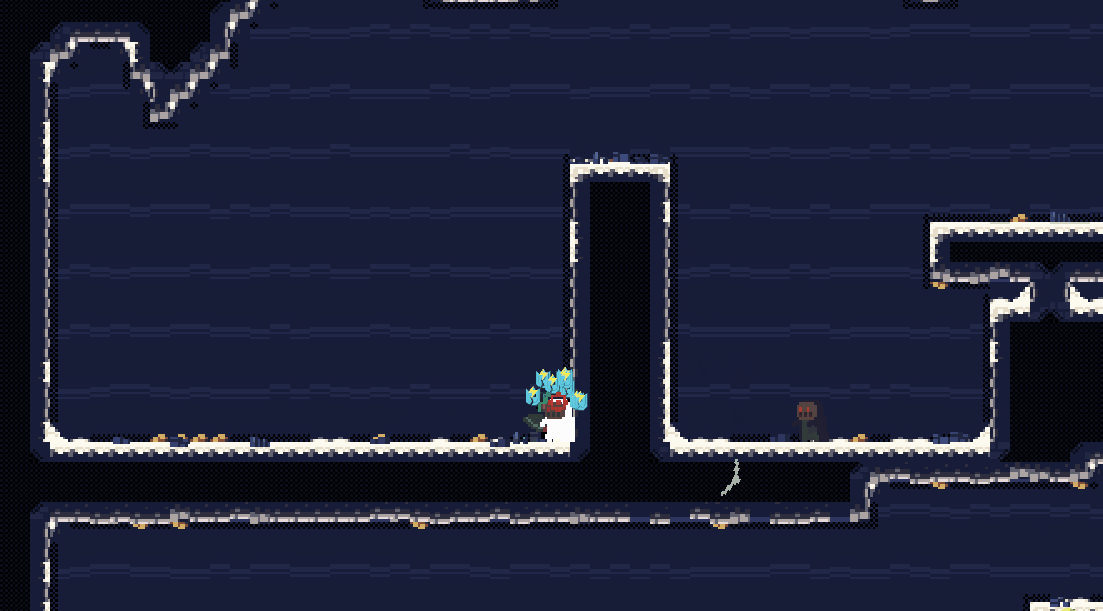
总结来看,在2D横板游戏中,相机设计直接影响到游戏体验。合理的相机跟随方式可以提升玩家的沉浸感和舒适度,预判和边缘跟随等方式适配于不同的游戏节奏和场景需求;相机的注意力吸附功能则能有效引导玩家关注关键元素,提升游戏互动性和趣味性;而多样化的相机震动设计通过巧妙的组合使用,为游戏增加了更多的动态反馈和沉浸感。这些设计要素不仅体现了游戏的艺术性和技术性,也强调了设计者对玩家体验的深刻理解和创新思考。未来的相机设计可以更加智能化和动态化,进一步丰富游戏的表现力和互动体验。
在2d横板游戏中,相机的设计是一个非常重要的部分,它直接影响到玩家的游戏体验。一个好的相机设计可以让玩家更好的体验游戏,而一个不好的相机设计则会让玩家感到不适,有的游戏将相机和关卡设计到一起,更是可以让游戏更加有趣。
在这篇文章中,我简单聊聊2d横板游戏中相机的设计。我们将会从 相机的跟随方式、相机的注意力吸附、相机的震动 这三个方面来讨论相机的设计。
当然围绕相机还可以做出很多有意思的有关于视觉方面的机制设计,但是这并不是本次分享的重点。
在2d横板游戏中,相机的跟随方式有很多种,比如 固定跟随、平滑跟随、预判跟随、延时跟随 等等。不同的跟随方式适用于不同的游戏,下面我们来看看这几种跟随方式的特点。
固定跟随是最简单的一种跟随方式,相机会始终跟随玩家,不会有任何延迟。这种跟随方式适用于一些简单的游戏,比如一些小游戏或者一些简单的横板游戏。这里不再赘述。
平滑跟随是一种比较常见的跟随方式,相机会有一个延迟,玩家移动时,相机会慢慢跟上玩家。这种跟随方式可以让玩家感到更加舒适,不会有太大的晃动感。这种跟随方式适用于一些需要玩家感到舒适的游戏,比如一些休闲游戏或者一些简单的横板游戏。
这种跟随方式比较适合慢节奏的游戏,这种方式的镜头移动较为平滑,不会有太大的晃动感,但是对于一些快节奏的游戏来说,延时的视角会让玩家无法第一时间获取想要的信息,这时候就需要使用预判跟随。
预判跟随是一种比较高级的跟随方式,相机会根据玩家的移动方向和速度来计算相机的位置,从而使得相机会提前“预判”玩家的移动。
在大多数平台跳跃游戏中,已经走过的地方不再重要,玩家更关心的是即将到来的地方。因此,预判跟随是一个非常好的选择。

延时跟随是一种比较特殊的跟随方式,在玩家移动后,相机会有一个较短的延迟,然后才会跟上玩家。
使用这种方式可以避免相机的大幅度晃动,并且增加真实感。
边缘跟随是一种比较特殊的跟随方式,相机不会移动,直到玩家移动到镜头的边缘,相机才会调整位置。这种跟随方式适用于一些地图设计对于游玩影响较大的游戏,比如说一些难度较高的平台跳跃游戏(《蔚蓝》就是一个很好的例子),或者一些boss战中。
在这种游戏中,玩家需要更多的注意力来控制自己相对于地图的位置,而不是相对于相机的位置。这种跟随方式其所产生的晃动和视角变化较少、可以让玩家更加专注于游戏的地图设计。
边缘跟随并不一定是同时作用于xy轴,实际上更为常见的是只作用于x轴,这样可以让玩家在y轴上更好的控制自己的位置。
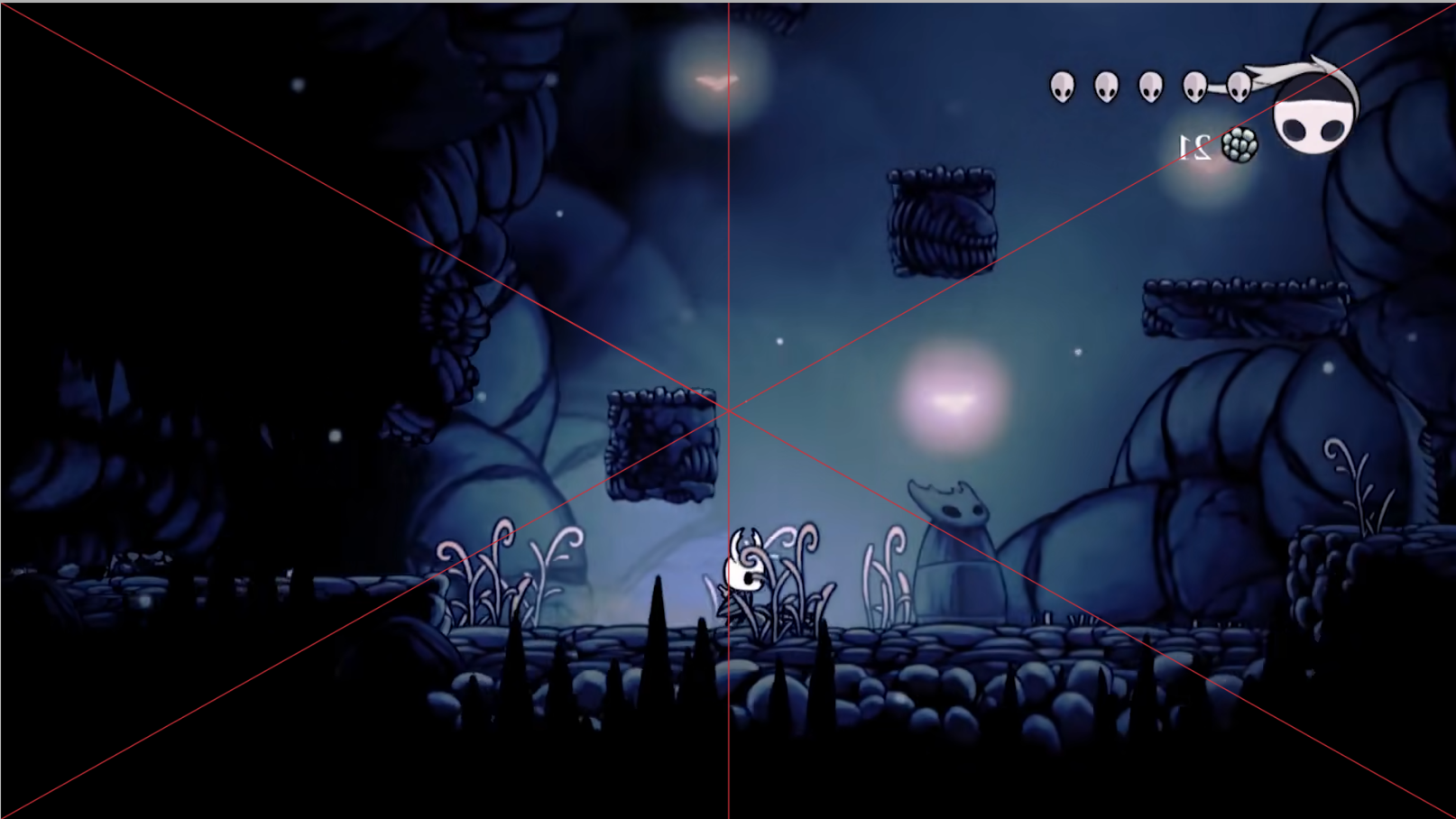
在实际的相机设计中,我们常常会混合使用多种跟随方式。以《空洞骑士》为例,我们可以看到相机在不同的场景中使用了不同的跟随方式,在大多数场景中,使用的实际上是延时跟随,但是在一些特殊的场景中,比如boss战中,使用的是 x轴固定视角,y轴延时跟随。

《精灵与萤火意志》中,使用的也是延时跟随,其延时相较于《空洞骑士》更长,同时镜头也要更远一些。

但是在追逐战中,其使用的是预测跟随 
在游戏过程中,我们的注意力不一定都在玩家身上,有时候我们需要让玩家注意到一些特殊的地方,比如说一些隐藏的道路、一些隐藏的宝藏、一些隐藏的敌人等等。这时候,我们就需要使用相机的注意力吸附功能。
什么样的吸附是合理的?这个问题没有一个固定的答案,但是我们可以总结出游戏中常见的吸附方式。
直接吸附是一种比较简单的吸附方式,当需要玩家注意某个地方时,相机会移动到这个地方,然后再慢慢移动回来。比如这个地方,它将相机直接移动到了登场的新敌人身上:

中心吸附是一种比较常见的吸附方式,当需要玩家注意某个地方时,相机会移动到该地方和玩家的中心位置。

4:6吸附比较少见,常见于两个角色对话的时候,相机会平滑移动到两个角色的 4:6 位置,这样可以让玩家更好的看到两个角色,同时强调当前说话的角色。 (我忘了是什么游戏来着的,使用了这种方式)
这种镜头比较有意思,整个屏幕实际上会被分成四个部分,A左边,A右边到摄像头,摄像头到B左边,B右边,它们的比例为 3:4:6:1。
你会发现,对于A来说它位于左半边屏幕的近似于居中的位置,而对于B来说它位于右半边屏幕的近似于边缘的位置,这样可以让玩家更好的看到两个角色,同时强调当前说话的角色。
比起使用直接吸附,它的视角移动没有那么突兀,比起使用中心吸附,它的视觉焦点更加明确。
相机的振动一般会使用下面几种方式: 1. 随机偏移震动 2. 随机连续振动 3. 定向弹簧振动
一般会使用上述三种振动进行组合,来达到较为理想的效果
会发现,这种振动会有一点点生硬,但是同时也较为的强烈。
这种振动由随机数生成,每一帧都会有一个随机的偏移量,这样就会产生一个随机的振动效果。随机数的选取可以选择直接的random,但是更好的方式是使用perlin noise,这样可以产生一个更加自然的振动效果。
这种振动会比较平滑,但是同时不够强烈。它的特征是由一组连续的数控制振动。
一般会使用 sin/cos 来控制振动的幅度 + 随机步长 来控制振动的幅度,当然也可以直接使用随机的dx,dy来控制振动,但是那样,镜头有一定概率朝一个方向连续移动,需要使用别的方式来限制振动范围和方向。
模仿弹簧,拥有 spring 和 damping 两个参数,控制弹性系数以及阻尼系数。从而产生一个类似于弹簧的振动效果。
它的优势就是方向明确,振动幅度逐渐减小,用来提示受到某个方向的冲击会比较合适。
一般会使用上述三种振动进行组合,来达到较为理想的效果。比如说,当玩家受到攻击时,可以使用定向弹簧振动,当玩家受到爆炸时,可以使用随机连续振动,当玩家受到地震时,可以使用随机偏移震动。
比如下面的这个打击效果就是同时使用了定向的弹簧振动以及较弱的随机连续振动
总结来看,在2D横板游戏中,相机设计直接影响到游戏体验。合理的相机跟随方式可以提升玩家的沉浸感和舒适度,预判和边缘跟随等方式适配于不同的游戏节奏和场景需求;相机的注意力吸附功能则能有效引导玩家关注关键元素,提升游戏互动性和趣味性;而多样化的相机震动设计通过巧妙的组合使用,为游戏增加了更多的动态反馈和沉浸感。这些设计要素不仅体现了游戏的艺术性和技术性,也强调了设计者对玩家体验的深刻理解和创新思考。未来的相机设计可以更加智能化和动态化,进一步丰富游戏的表现力和互动体验。
今天上工程实训课,需要使用u盘进行文件拷贝,但是当插入U盘并且打开之后,发现U盘内并不是正常U盘的样式,而是被改为了一个显示着盘符以及驱动盘名称的“快捷方式”。
我之前也遇到过这个病毒,初步尝试格式化U盘是否生效,但是并未奏效。而学校的电脑的环境没有网络,我也无法下载杀毒软件,所以只能手动查杀。
首先查看 那个顶替了
U盘正常文件夹的快捷方式的属性,发现其实际为使用cmd命令创建的快捷方式,其目标为C:\Windows\System32\cmd.exe /c start ./___/drivemgr.exe && start "" "./___" && exit。
可以发现,实际上其将所有文件存储在了___文件夹中,并且进行了隐藏,使正常无法看见文件夹。其次,其穷的那个了一个drivemgr.exe文件,这个文件是病毒的核心文件,其会在U盘插入时自动运行,将U盘内的文件夹隐藏,并且创建一个快捷方式,将原文件夹隐藏。当尝试格式化或者删除快捷方式的时候,它会重新在U盘内创建一个快捷方式。
其原理为诱导用户点击快捷方式,从而运行drivemgr.exe,从而使得病毒持续运行在系统中,并且感染其他插进来的U盘。
drivemgr.exe文件当打开
显示隐藏的文件的时候,会发现并不能够看见___文件夹,这是因为其将其设置为了
系统关键文件,而系统默认是不显示的,需要在文件夹选项中进行设置。
文件夹选项 -> 查看 -> 取消勾选“隐藏受保护的操作系统文件(推荐)”
-> 确定。
之后,你将能够看到___文件夹以及drivemgr.exe文件。
这类病毒一般会在C盘根目录下偷偷创建一个以数字命名的文件夹,里面存放一个和正常系统程序同名的exe文件,然后在注册表中添加一个自启动项,使得这个exe文件在系统启动时自动运行。
我们需要首先找到这个文件夹,之后在进程列表里面找到这个进程(注意打开任务管理器的显示路径,确认是处于该文件夹的进程,以防误伤系统进程),并且结束进程。
之后,删除该文件夹,此时病毒已经被停止。
删除drivemgr.exe文件之后,我们可以将___文件夹中的文件复制到U盘根目录,之后删除___文件夹,即可还原U盘文件夹。
这类病毒一般是通过U盘传播的,所以在使用U盘的时候,一定要注意查看U盘内的文件是否正常,不要随意点击快捷方式,以免感染病毒。
在电脑中,一定要安装杀毒软件,定期查杀病毒,以防止病毒感染。
学校的电脑使用环境复杂,很多人都会使用U盘,所以一定要注意自己的U盘是否被感染,以免传播病毒。