AI绘画入门学习-第一天
Day 1:安装环境与基础生成
学习目标:完成Stable
Diffusion本地部署,生成第一张AI图片。 - 实践步骤: 1.
下载秋葉整合包(解压密码:bilibili@秋葉aaaki),安装.NET依赖项,双击启动器一键运行。
2.
打开WebUI界面(默认地址http://127.0.0.1:7860),输入简单提示词(如“1
girl, masterpiece”),生成测试图。 3.
熟悉界面功能:模型切换、提示词输入区、生成参数(采样方法、迭代步数)。 -
检验成果:成功生成一张基础图片(如猫或人物)。 -
学习资料: - 秋葉整合包安装教程:CSDN博客。
- 界面功能速查表(见下文)。
安装秋葉整合包
参考大佬本人的视频,下面有网盘链接,下载后解压、安装依赖、运行程序即可:
运行程序后,打开窗口: 
这里面提供了非常多的可选配内容,但是我们先不管这些,点击右下角的一键启动即可打开程序的主页面,如果页面没有弹出来可以手动打开一下http://127.0.0.1:7860/
这个是默认的端口
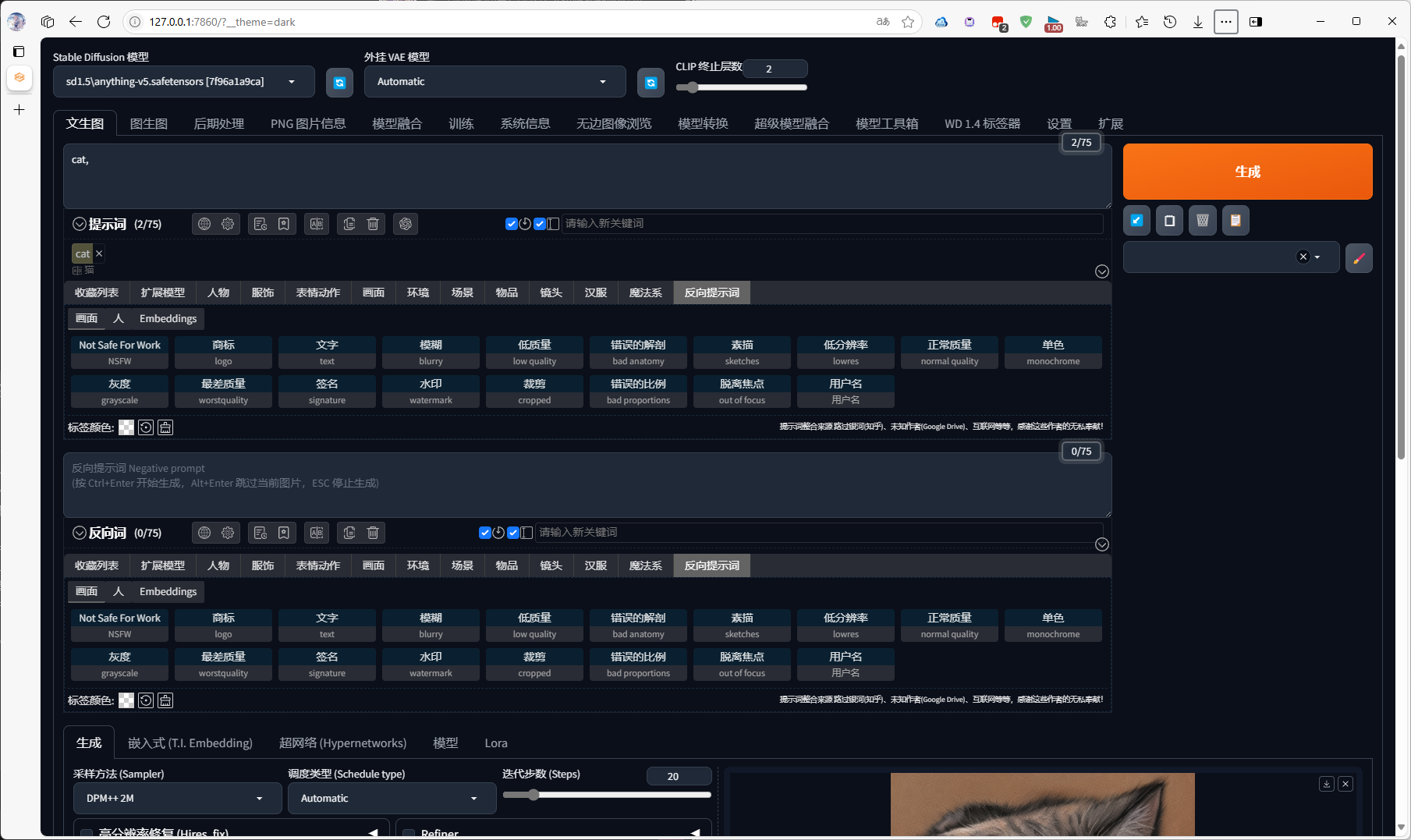
测试生成
在提示词框里面输入 cat ,生成了一只猫猫作为测试,效果还算是不错
延伸了解
进阶了解如何使用web ui
页面里面有非常多的ui按钮之类的东西,较为复杂,下面是教程中的一图流介绍:
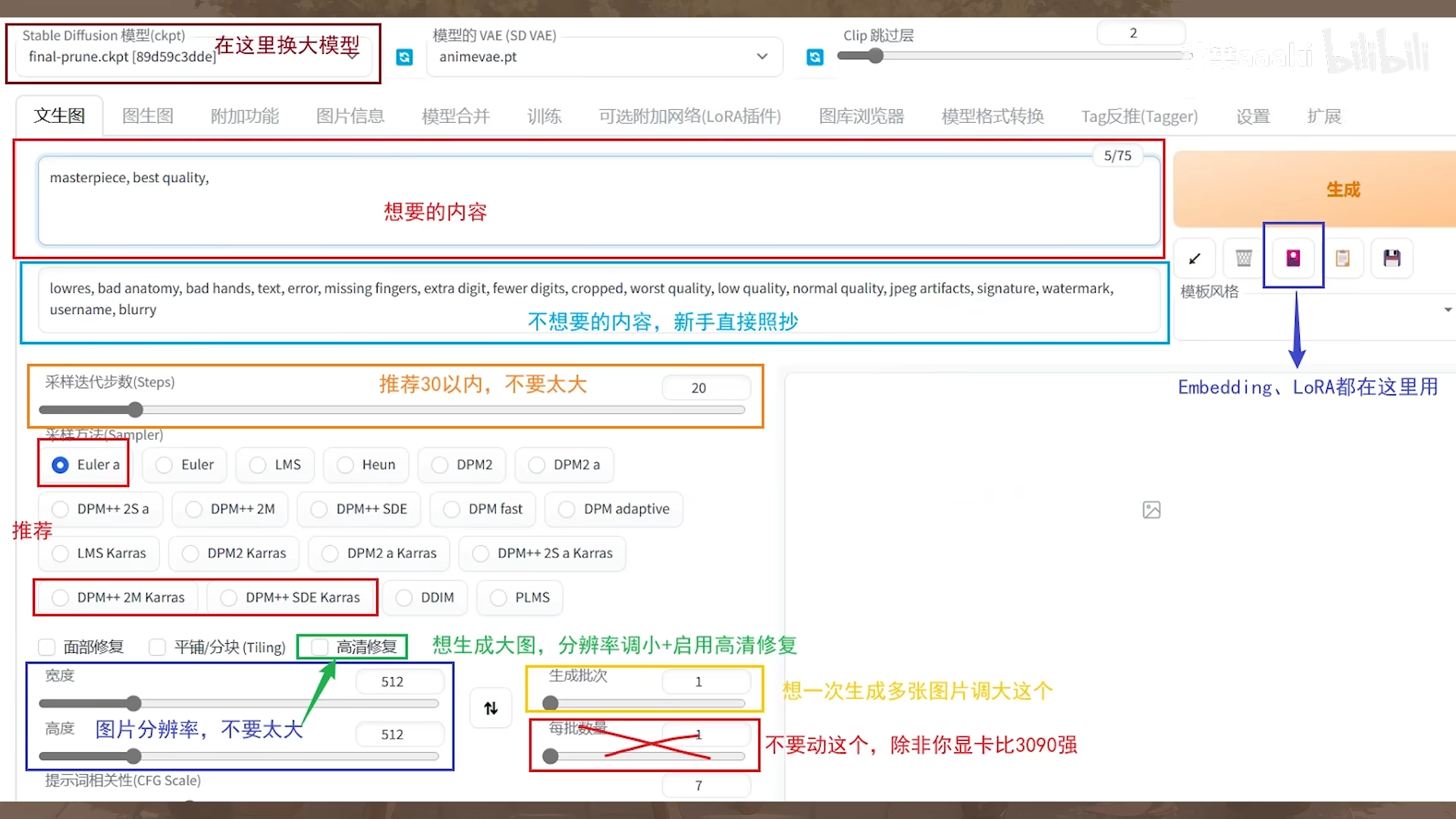
【AI绘画】从零开始的AI绘画入门教程——魔法导论【持续更新】
通过阅读这篇文章能够对于ai绘画有一个初步的了解。
这里把文章搬运过来,并且用我自己的话做标注:
标签?tag?
文生图本质是 tag 生成 图片,而非自然语言,文生图对于自然语言的处理和理解实际上都不是很到位。
整合包里面内置了一个tag提示词补全的插件,如果不知道那些 Tag 好,可以使用标签超市
https://tags.novelai.dev/
正面 Tag(想要的内容)是这些,改善画质用的 Tag:
masterpiece, best quality,
通用反面 Tag(不想要的内容),保底不出古神用的 Tag:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
Tags编写指南
wow,在评论区捡垃圾的时候捡到好东西了,这里单独开一个文本用作对于这篇文档的研读:
[[AI绘画-研读《Tags基本编写逻辑及三段术式入门与解析》]]
使用X/Y图表
在生成图片时候,可以使用x/y图表快速生成不同参数的图片进行对比。 
进阶学习
带师级别使用
继续看完 【AI绘画】从零开始的AI绘画入门教程——魔法导论【持续更新】 - 哔哩哔哩
的后面的部分吧,这里就不赘述了。
| ## AI 给我提的建议: |
| ### Day 1 学习记录分析与建议 |
| 从你的学习记录来看,你已经成功完成了环境部署和基础生成,并开始探索提示词(Tag)编写和参数对比工具。以下是对你当前进展的总结与后续学习建议,结合你的目标和搜索结果优化学习路径: |
当前成果总结
- 环境部署成功:通过秋葉整合包一键启动WebUI,并生成基础图片(如猫),验证了硬件配置的兼容性。
- 初步探索提示词:了解了正面/负面Tag的作用,并尝试使用标签超市优化生成效果,符合提示词编写的基本逻辑。
- 工具使用:尝试X/Y图表进行参数对比,这是优化生成效果的重要技巧。
优化建议与下一步学习方向
1. 完善提示词结构
- 当前不足:你的测试提示词较简单(如“cat”),需进一步学习结构化描述。
- 改进方法:
- 使用“三段式”提示词:主体+细节+风格+质量(如“a fluffy white cat, blue eyes, sitting on a windowsill, soft lighting, anime style, 8k”),参考网页5提到的提示词手册。
- 权重控制:通过
(keyword:1.5)增强关键元素,例如(cat:1.3)提升猫的细节优先级。
2. 模型管理与风格切换
- 下一步目标:下载不同风格的大模型(如动漫风
Anything V5或写实风Realistic Vision),放入models/Stable-diffusion目录并切换使用。- 推荐资源:Civitai模型库(https://civitai.com/),筛选高评分模型。
- 实践任务:用同一提示词生成不同风格图片(如“cat”分别用动漫和写实模型输出),对比效果差异。
3. 参数优化与X/Y图表进阶
- 当前实践:初步使用X/Y图表,但需系统学习参数组合。
- 进阶方法:
- 对比采样方法:测试不同采样器(如
DPM++ 2M Karras和Euler a)对图像细节的影响。 - 调整CFG值:设置X轴为CFG Scale(7-12),观察提示词贴合度与图像锐化程度的变化。
- 对比采样方法:测试不同采样器(如
4. 插件预装与后续准备
- ControlNet插件:提前下载ControlNet模型文件(如
canny和openpose),放入models/ControlNet目录,为Day 4的精准控制做准备。 - LoRA模型:从Civitai下载角色类LoRA(如《原神》角色),放入
models/Lora目录,便于后续角色定制。
学习资源补充
- 提示词手册:参考网页5提到的《Tags基本编写逻辑及三段术式入门与解析》,系统性学习标签组合。
- 视频教程:观看B站秋葉整合包配套教程(如Day 1提到的视频),直观学习界面操作。
- 社区案例:浏览Civitai的图片生成案例,分析他人使用的提示词和模型组合。
后续计划衔接
- Day 2(提示词与参数):尝试生成复杂场景(如“赛博朋克城市夜景,霓虹灯光,雨天”),结合权重和负面Tag优化细节。
- Day 3(风格控制):用不同模型生成同一主题,总结风格差异(如动漫风的扁平色彩 vs. 写实风的光影层次)。
- Day 4(角色控制):使用ControlNet固定线稿,生成与预设一致的角色形象。
检验学习成果的标准
- 基础生成:能生成无明显畸变的复杂场景图(如“骑士骑马冲锋,背景雪山”)。
- 风格控制:同一提示词可输出3种以上风格(如像素风、水墨风、厚涂油画风)。
- 效率提升:通过X/Y图表快速筛选出最佳参数组合(如采样器+CFG值)。
按此方向深化学习,后续目标将水到渠成。遇到具体问题可随时查阅秋葉整合包的B站评论区或CSDN教程! 🚀