2d游戏中的相机震动
为什么我们需要相机震动
相机震动可以让游戏 feel 更 “好”,具体而言,
- 增强反馈:相机震动可以在玩家执行某些动作时提供即时反馈,例如攻击、跳跃或受到伤害。这种反馈可以让玩家更好地理解他们的行为对游戏世界的影响。
- 增加沉浸感:通过模拟真实世界中的相机运动,游戏可以让玩家感受到更强的沉浸感。例如,在激烈的战斗场景中,微妙的相机震动可以让玩家感受到紧张和刺激。
- 提升游戏节奏:相机震动可以用来强调游戏中的关键时刻,例如击败敌人或完成任务。这种视觉上的强调可以帮助玩家更好地理解游戏节奏和重要事件。
了解震动
震动的类型
游戏中的振动无非是模仿现实中的振动,了解现实中的振动,我们可以更好的设计游戏中的振动。
首先,按照目标来看,震动可以分为以下几种类型:
- 位置震动:相机在空间中的位置发生变化。
- 旋转震动:相机的朝向发生变化。
- 缩放震动:相机的缩放级别发生变化。
- 混合震动:同时应用位置、旋转和缩放的震动。
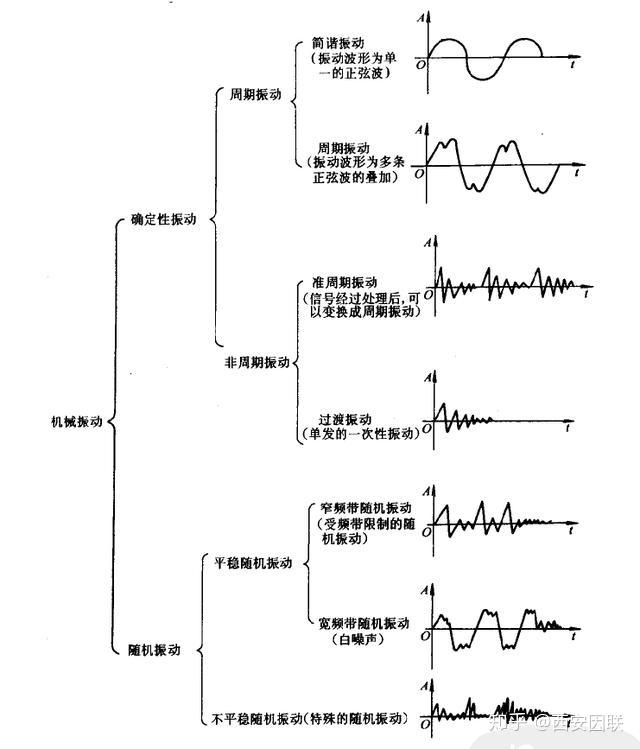
其次,按照震动的特征来看,震动可以分为以下几种类型: 1. 简谐震动:震动的幅度和频率是恒定的。 2. 阻尼震动:震动的幅度随着时间逐渐减小。 3. 各种非线性震动:震动的幅度和频率不是线性关系。
如果按照震动的规律来看,震动可以分为以下几种类型: 1. 简谐振动 2. 周期振动 3. 准周期振动 4. 过渡振动 5. 窄频带随机振动 6. 宽频带随机振动 7. 不平稳随机振动
对于人眼的感知
但是上面的那么多震动类型,对于人眼来说,实际上是比较难以分辨的。比如下面两种震动方式:

这里依次播放了两种震动模式,一个是窄频带随机震动,一个是不平稳随机震动。
 这里依次播放了两种震动模式,一个是阻尼震动,一个是弹簧震动,它们在频率分布或者振幅分布上拥有特殊的规律。
这里依次播放了两种震动模式,一个是阻尼震动,一个是弹簧震动,它们在频率分布或者振幅分布上拥有特殊的规律。
人眼对于震动的感知可以分为两个部分: 1. 基于 运动感知 的 瞬时感知 2. 基于 模式识别 的 持续感知
对于瞬时感知,人眼对于震动的频率非常敏感,尤其是高频震动。对于持续感知,人眼更擅长于识别震动的模式和规律。
设计震动
我们 基于上述的震动类型和人眼的感知特点,可以设计出更符合玩家体验的震动效果。
匹配人眼的瞬时感知
查看下面的两种震动方式: 
我们可以发现,如果是使用随机偏移生成的震动,它会看起来非常“难受”,这种不适感有两个成因: 1. 瞬时感知困难:是因为对于一个人眼来说,随机偏移将会使得在短时间内,物体发生过大的位移,导致人眼对于运动的感知存在一定的困难。 2. 频率过高:是因为随机偏移的震动频率理论上是无限的(实际和帧率有关),而人眼对于高频震动的感知是非常敏感的。这种高频震动会让人感到不适。
或许你可能会认为还好,但是如果是看下面这个对比(仅仅是将原本的小球替换为了多个点):